
대회 주제:
인공지능을 활용하여 디지털 확산을 촉진하고 디지털 취약 계층의 문제 해결 및 혁신적 솔루션 탐색

보이스캐너:
보이스(Voise) + 스캐너 (Scanner)를 합친 단어로, 전화통화시 상대방의 목소리를 분석하여
보이스피싱인지 아닌지 구분하여 의심상황 발생시 경고 메세지 전송하는 어플 제작하기로 하였다.
보이스캐너를 떠올리게 된 계기:
친구와 함께 있었는데 친구가 전화를 받고 갑자기 저보고 조용히 하라면서 혼자 어디론가 가려고 했다. 하지만 근처에서 전화내용을 들어 본 결과 보이스피싱이라는 의심이 강하게 들었고 친구에게 보이스피싱이라고 말을 했으니 믿지 않음. 결국 자칭 검사(?)와 카카오톡까지 주고받고 검찰송치가 된다면서 사무실로 오라는 이야기까지 듣고 제가 옆에서 말렸고, 친구가 의심을 하기 시작했고, 그렇게 전화를끊을 수 있게 되었다. 이때의 기억이 떠올라 만약 옆에 사람이 없을때 친구가 이런 전화를 받았다면 어떻게 되었을까? 보이스피싱 수법에 관한 안내정보를 노년층에 비해 비교적 많이 접하는 청년층도 이렇게 위험한데 노년층 인구에게는 더 위험하겠다 라는 생각이 들었다. 그래서 옆에서 조언을 해줄 수 있는 사람대신 같은 기능을 제공하는 어플을 만들어 제공하면 좋겠다. 라는 생각을 하게 되었다.
보이스캐너 기대 기술 구현 :
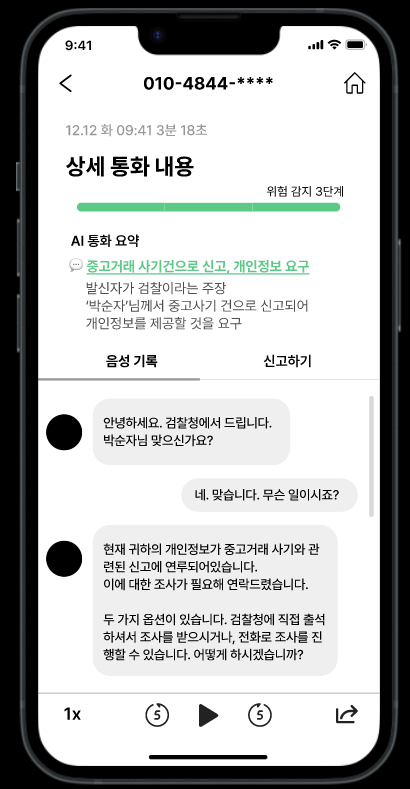
1. 통화중 보이스피싱에 해당하는 대화흐름을 감지하고 사용자에게 안내메세지와 대응방법을 전송하며 보호자에게 대화 내용을 텍스트로 전송한다.
2. 금융 어플리케이션 잠금기능 및 즉각적인 전화번호 신고기능을 제공한다.
3. 현재 통화 내용에 대해 물어볼 수 있는 챗봇서비스를 제공한다.
4. 3차 경고 이후에도 통화가 지속된다면 등록된 보호자의 번호로 통화음성 텍스트를 전송하여, 현재 통화 대상자의 통화상황을 공유한다.
5. 경찰 및 은행, 보안기업과 파티너쉽을 통해 안전성과 데이터셋을 보완하고 지속적인 업데이트를 기대한다.
보이스캐너 시연:
 |
 |
 |
 |
 |
 |
 |
 |
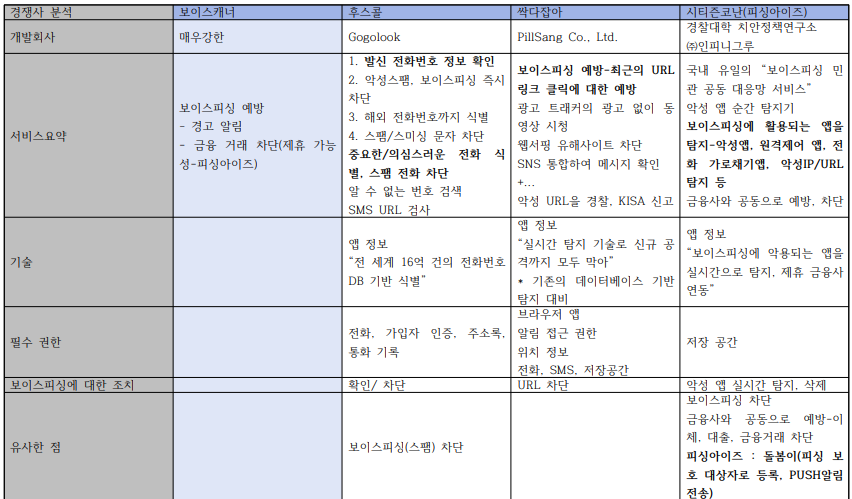
시장분석:
사용한 데이터:
1. 금융감독원 홈페이지의 그놈목소리 자료를 크롤링으로 다운받음
2. AI Hub의 한국인 대화음성 데이터 사용
모델 생성과정:
1. 다운받은 보이스피싱 음성데이터를 텍스트로 변환
2. Colab의 환경에서 python의 requests 라이브러리를 이용하여 HTTP 요청을 보내는 형식으로 Azure를 이용함
3. konlpy를 사용하여 텍스트 데이터를 전처리함
import os
import pandas as pd
from konlpy.tag import Okt
from collections import Counter
# Okt 객체 초기화
okt = Okt()
# 대화 내용이 저장된 파일을 찾는 함수
def find_text_files(directory):
return [f for f in os.listdir(directory) if f.endswith('.txt')]
# 텍스트 파일에서 명사 추출
def extract_nouns(filepath):
with open(filepath, 'r', encoding='cp949') as file:
text = file.read()
nouns = okt.nouns(text)
return Counter(nouns)
# 모든 파일에서 명사 추출 및 하나의 CSV 파일로 저장
def process_all_files_to_single_csv(directory, csv_filename):
all_frequencies = {}
for filename in find_text_files(directory):
filepath = os.path.join(directory, filename)
frequency = extract_nouns(filepath)
all_frequencies[filename] = frequency
# DataFrame 생성
df = pd.DataFrame.from_dict(all_frequencies, orient='index').fillna(0)
df.to_csv(csv_filename, encoding='utf-8-sig')
print(f"{csv_filename} 파일이 생성되었습니다.")
# 디렉토리 경로 및 CSV 파일명 지정
directory = 'C:/hackertone/voice_phising_txt' # 디렉토리 경로
csv_filename = 'nouns_frequency.csv' # 생성할 CSV 파일명
process_all_files_to_single_csv(directory, csv_filename)한국인대화 데이터도 위와같은 방식으로 단어를 추출하여 하나의 csv 파일로 만든다.
4. 합쳐진 하나의 csv파일로 머신러닝을 진행한다.
사용한 모델은 randomforest, Lasso를 사용하였다.
결과:
모델이 과적합이 되었다.
문제를 생각해보니
1. 보이스피싱데이터와 일반인대화 데이터의 수가 적었다.
2. 한국어 텍스트 분석에 최적화된 kobert모델을 사용하지 않았다.
이 두가지가 모델이 과적합된 주요 원인이라고 분석하였다.
이렇게 모델 구현과 피그마를 통한 시연과 발표 피피티까지 작성을 하였다.
퓨처 플랜으로는
1. 챗봇
2. 금융어플 잠금
3. 보호자에게 전화음성을 텍스트로 변환하여 전달
이 있다.
소감:
내가 어떤 기능을 구현하는 모델을 만들고 싶다고 생각하고
팀원들과 코드를 짜고 문제를 검토하고
어떠한 기능이 추가되었으면 좋겠다고 이야기하며 개발을 하는 순간이 너무 재미있었습니다.
'• 자격증 > AI-900' 카테고리의 다른 글
| [K 디지털 플랫폼 AI 대회]초광역권 인공지능 공동교육 과정 성과공유회 (1) | 2024.01.15 |
|---|---|
| [AI900][K디지털플랫폼 AI 경진대회] 본선 후기01 / 마이크로소프트 애저 / 인공지능을 활용한 디지털 격차 해소 아이디어 / 보이스피싱 보이스캐너 (1) | 2024.01.04 |
| [AI-900] AI-900 시험범위 전체 요약정리 / 문제풀이 사이트 / 합격 꿀팁! (3) | 2023.12.26 |
| [AI-900] 자격증 취득 후기 및 배지 획득방법/ 자격증 출력방법 (1) | 2023.12.07 |
| [AI-900] AI-900 자격증이란? + 시험범위/ 공부사이트/ 접수방법 (0) | 2023.12.02 |