
● 시험범위
(1) 책임있는 AI (responsible AI)
(2) 머신러닝 (machine learning)
(3) 컴퓨터비전 (computer vision)
(4) NLP (natural language processing)
제가 생각하기에 주요한 내용만 정리하였습니다
해당 개념을 외운뒤, 기출문제 몇번 풀어보시면
통과기준인 700점은 쉽게 넘기실 수 있을 것 같습니다!
저는 시험 보기 전까지
아래에 있는 개념암기 + 기출 100문제 정도 풀어보았습니다.
자격증은 921점으로 취득 할 수 있었습니다.
(공유하실때 출처 링크 꼭 남겨주세요)
(1) 책임있는 AI (Responsible AI)
* 6가지 키워드
1. 공정성(Fairness)
: 대출프로그램에서 성차별, 인종차별안됨, 데이터의 편향(bias)을 반영해서는 안됨
2. 신뢰성 & 안정성(Reliability & Safety)
: 0.5이상이면 암, 이하면 정상이라고 판단하는 암진단모델에서
만약 값이 안채워지면 자동으로 0으로 입력한다면
평균이 떨어져->판단기준 바뀜(암인데 정상으로 진단 or 정상인데 암으로 진단)
3. 보안 & 개인정보(Privacy & Security)
: 개인의 질병 유무를 유출해서는 안됨
4. 포괄성(Inclusiveness)
: 장애인을 위한 배려(고대비,돋보기,읽어주기,받아쓰기 등)
5. 투명성(Transparency)
:모델의 판단의 근거와 이유를 설명가능해야함
대출이 안되는 근거 설명, 알고리즘의 원리
6.책임감(Accountability)
: AI가 의사결정을 할 때 사람이 그 결정을 무시할 수 있어야함
AI가 핵폭발 버튼을 눌러야 한다고 판단 -> 인간이 멈추기 가능해야함
(2) 머신러닝 (Machine Learning)
머신러닝: 과거의 데이터를 기반으로 미래를 예측
1. 회귀(Regression) -지도학습, Lable 알고있음
2. 분류(Classification) -지도학습, Lable 알고있음
3. 군집(Clustering) -비지도학습, Lable 모름
1.회귀:
EX.날씨에 따른 운동량 예측
1.학습군, 검증군 데이터 나움
2.함수의 형태로 학습군을 반영하는 모델을 만든다
3.검증데이터를 사용해 모델을 검증한다.
● 회귀 평가 매트릭 및 권장사항
-1. R-제곱(R-SQUARED) :선형회귀 모델의 예측력을 나타내는 지표
-2. 평균절대오차(MAE,MEAN ABSOLUTE ERROR):에러를 절대값 취해서 평균을 취함
-3. 제곱손실(평균제곱오차): 오차를 제곱해서 평균을 취함
-4. 평균제곱오차(RMSE, ROOT MEAN SQUARE ERROR):에러를 제곱하고 절대값후 루트취함
2.분류: 이유있게 데이터를 묶어
-데이터의 결고값이 0 OR 1
-다중분류라면 값이 0,1,2
1. 훈련데이터, 검증데이터 나누기
2. 데이터의 학습된 결과로 어떠한 결과값이 나옴
3. 시그모이드 합수 로지스틱 회귀함수 등으로 0에서 1사이의 값으로 반환 시키면서
결과값 >0.5 -> 1 CLASS
결과값 < 0.5 -> 0 CLASS
● 분류성능평가
-1. 검증데이터로 모델이 반환한 0,1 예측값과 정답 데이터를 비교해 TP,FP,TN,FN ->CONFUSION MATRIX
-2. 정확도 = TP+TN / 전체 개수
* confusion matrix
P=양성
N=음성
T=예측값이 실제값과 동일함
F=예측값이 실제값과 다름
| 예측 | |||
| 실제 | P | N | |
| P | TP | FN | |
| N | FP | TN | |
아래 예제와 같은 confusion matrix 예제 꼭 풀어보기!

3.군집: 묶고나서 공통점 찾아
-정답데이터가 존재하지 않는다
-K-MEANS가 대표적
-먼거리= 특징값이 떨어져 있다.
SAMPLE 간의 간격이 가깝도록 중앙점은 이동하면서 학습함
면적이 가장 작아지는 지점을 군집이라고 함
● 학습하는 과정중 중요한점
1.데이터
2.데이터를 학습하고 평가하는 과정
● 과정:
1. 데이터를 훈련세트와 검증세트로 분할
2.학습데이터를 모델에 맞추는 알고리즘 적용
3.학습된 모델은 데이터의 관계를 캠슐화 = 학습된 모델
4. 모델을 사용하여 검증 데이터에서 예측 생성
5. 평가 매트릭을 사용하여 예측 레이블과 실제 레이블을 비교하여 클러스터 분리(비지도)를 측정
6. 1-5를 반복
*모델에서 데이터가 떨어진 정도=편차
(2-1) AZURE의 머신러닝
1. 기계학습을 위한 클라우드 기반 플랫폼
: 컴퓨팅환경, DATASET, 평가도구, 모델 서비스를 제공함
2. 머신러닝 모델을 자동으로 최적의 알고리즘으로 학습해주는 플랫폼
3. 데이터와 원하는 감독 모델을 제공하고 애저 머신러닝이 최상의 모델을 찾음
:최적의 OPTIMIZED MODEL 선택
●azure ML designer (애저 머신러닝 디자이너)
1. 머신러닝 알고리즘을 block(블럭) or pipeline(파이프라인) 으로 구현
:데이터베이스 로딩, 전처리, 학습, 평가 과정을 시각화 툴을 이용해 개발함
2. 학습파이프라인을 이용해 모델 학습 및 평가
3.새 데이터에서 레이블을 예측하는 추론 파이프라인 만들기
4. 앱에서 사용할 서비스로 추론 파이프라인 배포
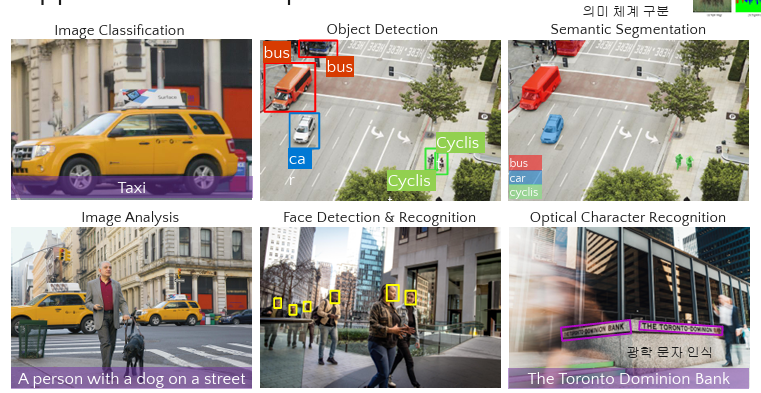
(3) 컴퓨터비전 (Computer Vision)
* 6가지 기술
1. 이미지분류(Image Classification)
: 같은 물체끼리 분류해
2. 이미지 탐지(Object Detection)
: 네모박스로 사물표시후 이름붙이기
3. 의미체계구분(Sementic Segmentaion)
: 픽셀로 사물에 색을 칠함
버스는 빨간색으로,차는 파란색으로 칠하기
4. 이미지분석(Image Analysis)
할아버지가 개와 함께 신호등을 건너고 있습니다 = 캡션달기
시각장애인에게 설명
5. 얼굴탐지&인식(Face Detection & Recognition)
얼굴만 전문적으로 탐지
6. 광학문자인식 (OCR)
사진에 있는 글자를 인식
(3-1) AZURE의 컴퓨터비전
*4가지 기술
1. Computer Vision
1-1. 이미지분석: 사진설명
1-2. 이미지탐지: 네모상자로 인식
1-3. 얼굴탐지: 얼굴만 중점으로 인식
1-4. smart cropping
1-5. OCR
2. Custom Vision: 나만의 데이터로 CV를 만드는것
2-1. 이미지 분류
2-2. 이미지탐지
3. Face: 얼굴만 탐지 & 인식
4. Form Recognizer: 영수증,송장,다른서류 인식 -형태가 고정되어 있는 양식 인식
(4) 자연어처리 (NLP)
* 5가지 키워드
1. 텍스트 분석 및 엔티티 인식
:ms, 삼성,타이레놀과 같은 엔티티를 인식함
:NER(named entity recognition)
2. 감정분석
:글을 읽고 긍정, 부정 인식, 리뷰, sns글의 긍정 부정 판단
:빠르고 객관적이다
3. 음성 인식 및 합성
:유투브 자막, 실시간 번역
4. 기계번역
:구글번역기
5. 의미체계적 언어 모델링
(4-1) AZURE의 자연어처리
● language
1. 언어 탐지
2. 핵심문구 추출
3. 엔티티 탐지
4. 감정분석
5. 질문답변
6. 대화형 언어 이해
● speech
1. text to speech
2. speech to text
3. speech 번역
● translator
1. text translator
● Azure Bot Service (conversation AI)
1. platform for conversational AI
● 클라우드 핵심기술: 확장성
● AZURE AI SERVICE
1. 애저 머신러닝
:기계학습 모델을 교유ㄱ,배포 및 관리하기 위한 플랫폼
2.cognitive service(인지 서비스)
:비전,언어, 말, 의사 결정의 4가지 주요 서비스가 포함된 서비스 제품군
: ms의 인지 서비스 = 구글의 딥러닝
3. 애저 봇 서비스
:대화하여 봇 개발 및 관리를 위한 클라우드 기반 플랫폼
4. 애저 인지 검색
:지능형 검색 및 지식 마이닝을 위한 데이터 추출, 보강 및 인덱싱
● cognitive service 에 2가지가 필요하다
1. rest endpoint :인공지능 서비스 위치 주소
2. authentication key: 인공지능 서비스 접속 키
● AI > ML > DL > GA (generative AI)
● cloud > AI > data
●open ai 플랫폼
1. 대화형 ai
2. 코딩,그림 서비스 (codex, DALL-E2)
3. 생성형 ai
학습사이트
https://www.examtopics.com/exams/microsoft/ai-900/view/
AI-900 Exam – Free Actual Q&As, Page 1 | ExamTopics
For a machine learning progress, how should you split data for training and evaluation? A. Use features for training and labels for evaluation. B. Randomly split the data into rows for training and rows for evaluation. C. Use labels for training and featur
www.examtopics.com
ai -900 자격증 시험 같은 경우에는 문제은행 식으로 출제되었던 문제가 그대로 출제되는 방식입니다.
따라서 문제를 많이 풀어볼 수록 고득점을 받을 수 있습니다.
위의 학습 사이트에서 최대한 많은 문제를 풀고 이해하고 외워가시면 자격증 취득은 쉬우실 거라고 생각합니다~!
문제를 풀기전에 위에서 제가 적어 놓은 키워드들의 카테고리와 키워드의 특징을 물어보고 분류하는 문제가 가장 많이 나옵니다.
예를들어
◆ 데이터세트에서 숫자값이 유사한 행그룹을 식별해야 한다. 어떤 유형의 ml을 사용해야 하는가? 라는 질문에
1. 회귀
2. 분류
3. 번역
4. 군집
이런 문제가 나왔다면 4. 군집을 선택 할 수 있어야 합니다.
◆ 모델의 예측에 영향을 미치는 데이터 값은? :피처(feature)
◆ 모델에서 예측되는 데이터 값 : 레이블(label)
◆ 집~직장 거리를 기준으로 출퇴근시 자전거 이용여부를 예측하는것 : 분류
이런 형태로 문제가 나오기 때문에
(1) 책임있는 AI (responsible AI)
(2) 머신러닝 (machine learning)
(3) 컴퓨터비전 (computer vision)
(4) NLP (natural language processing)
이 4가지 카테고리에 각각 어떤 키워드들이 있는지, 그 키워드들의 특징을 암기하는 것이 제일 중요합니다!
시험 보시는 모든 분들의 합격을 기원하면서 포스팅 마치도록 하겠습니다!
시험 화이팅하세요!
(공유하실 때 출처링크 꼭 남겨주세요)
'• 자격증 > AI-900' 카테고리의 다른 글
| [K 디지털 플랫폼 AI 대회]초광역권 인공지능 공동교육 과정 성과공유회 (1) | 2024.01.15 |
|---|---|
| [AI900][K디지털플랫폼 AI 경진대회] 본선 후기02 / 보이스캐너 프로젝트 리뷰 (0) | 2024.01.12 |
| [AI900][K디지털플랫폼 AI 경진대회] 본선 후기01 / 마이크로소프트 애저 / 인공지능을 활용한 디지털 격차 해소 아이디어 / 보이스피싱 보이스캐너 (1) | 2024.01.04 |
| [AI-900] 자격증 취득 후기 및 배지 획득방법/ 자격증 출력방법 (1) | 2023.12.07 |
| [AI-900] AI-900 자격증이란? + 시험범위/ 공부사이트/ 접수방법 (0) | 2023.12.02 |