
2023년 12월 18일부터 데이터분석 부트캠프를 진행하게 되었습니다.
오늘은 12월 29일로 시작한지 12일째 되는 날이네요!
친근한 엑셀로 실무 엑셀 데이터 분석및 기초 수학/통계 시작하기(이동훈 강사님)
데이터 파악하는 방법
▶ 피벗테이블: 엑셀에서 커다란 표의 데이터를 요약하는 통계표
1. 어떤 데이터를 EDA하는 제일 좋은 방법
2. 어떤 요약통계표를 만들고 싶은지, 어떤 데이터를 기준으로 테이블을 만들지 생각해야함!
3. 내가 만들어야 하는 피벗테이블을 손으로 그려보고 따라그리기!
▶ 결측치 처리 방법: 결측치의 유형 및 비율에 따라 적절한 결특치 처리 방법을 결정해야함
1. 제거 :가장단순하지만 통계적편향이 생길 수 있음. 데이터크기의 손실 발생.
2. 치환 :적당한 방법으로 대체하는것(평균), 단순대체하는 방법은 자료의 편향성이 높이고 특성들간의 상관관계를 왜곡할 수 있음. 데이터에 대한 도메인 지식이 있어야 효율적으로, 정확히 결측치 대체 가능
3. 모델기반처리: 결측치를 예측하는 새로운 모델을 구성해 결측치를 채워나가는 방식
▶ 결측치 종류
1. NA : 값이 유효하지 않음
2. NaN: 숫자가 아니다
3. Null: 아무것도 존재하지 않음
4. 빈칸: 데이터가 입력되지 않음
▶ 이상치: 지정된 그룹에 분류되지 못하는 값으로, 정산군의 상한과 하한의 범위를 벗어나 있거나 패턴에서 벗어난 수치
▶Z-SCORE: 자료가 평균으로부터 표준편차의 몇 배만큼 떨어져 있는지를 나타내는 지표
자료값-평균/표준편차
Z-SCORE 특징:
1. 양의값: 자료값이 평균보다 높다
2. 음의갓: 자료값이 평균보다 낮다
3. 0근사: 자료값이 평균과 비슷함
4.3이상이거나 -3이하면 일반적으로 이상치로 판한다나,상황에 따라 +-2가 기준이 되거나 +-4가 기준이 될 수 있음
▶ 상관분석: 두 변수가 어떤 선형적 관계를 갖고 있는지를 분석하는 방법
▶ 상관계수: 두 변수사이의 상관성을 나타내며 일반적으로 피어슨 상관계수를 사용
X,Y가 함꼐변하는 정도/X,Y가 각각 변하는 정도
1. 1에가까울수록 양의 상관관계(정비례), -1이 가까울수록 음의 상관 관계 (반비례)
2. 일반적으로 0.7 이상이면 강한 양의 상관관계
3. 일반적으로 -0.7 이하이면 강한 음의 상관관계
▶데이터 전(앞)처리의 개념:
1. 데이터 및 변수 형태 변환
2. 변수 선정
3. 결측치 및 이상치 처리
4. 데이터 분류
5. 데이터 분리 및 결합
6. 기타 데이터 가공 및 처리
-> 데이터 분석 과정 중 가장 많은 시간과 비용이 필요한 과정
다양한 함수의 종류와 기능, 문법 정리
▶ MATCH 함수
하나의 열이나 행을 잡아야 함
=MATCH("찾고싶은 문자" , 하나의 열 또는 행 범위 드래그 , 0)
=MATCH("F" , D1:D3 , 0)
=MATCH(C11, D1:D3 , 0)
▶ VLOOKUP 함수
=VLOOKUP( 중복된 값이 없는 컬럼에 입력된 셀(기준셀) , 기준셀부터 범위 선택 , 찾고싶은 컬럼의 순서 , 0)
=VLOOKUP(A4 , LIST!D:J , 3 , 0)
=VLOOKUP(A4 , LIST!D:J , MATCH(C11, D1:D3,0) , 0)
▶ 셀 & 셀
고유값이 없을 경우(=중복값이 있는경우) 행을 합쳐서 고유값을 만든다
=VLOOKUP( B5&C5 , LIST!D:J, 3 , 0)
▶ INDEX 함수
=INDEX(범위 , 범위의 첫 시작으로부터 몇번째 행 , [범위의 첫 시작으로부터 몇번째 열] )
=INDEX(A1:C3 , 2 , 3)
→ 행, 열의 숫자를 MATCH 함수로 대치 해주기!
▶ COUNT 함수
특정 범위에서 "숫자 데이터" 가 들어가 있는 셀의 개수 파악
=COUNT( 숫자 데이터의 개수를 파악할 셀 범위)
▶ COUNTA 함수
특정 범위에서 "모든 데이터" 가 들어가 있는 셀의 개수 파악
=COUNT( 값이 입력된 데이터의 개수를 파악할 셀 범위)
▶ COUNTA 함수
특정 범위에서 비어있는 셀의 개수 파악
=COUNT( 빈 셀의 개수를 파악할 셀 범위)
▶ COUNTIF 함수
특정 범위에서 하나의 조건을 만족하는 셀의 개수 파악
=COUNTIF( 데이터의 개수를 파악할 셀 범위 , "개수를 셀 데이터의 조건" )
=COUNTIF( C5:C12 , 1 )
=COUNTIF( C5:C12 , " >=5" ) # COUNTIF의 조건에는 ""가 붙는다!
▶ COUNTIFS 함수 #조건이 1개여도 사용가능!
특정 범위에서 2개 이상의 조건을 만족하는 셀의 개수 파악
=COUNTIFS( 범위1 , "조건1" , 범위2 , "조건2" )


★ 나이의 조건이 바뀌는 경우가 생기기 때문에 마지막 조건을 부등호만 " " 안에 넣어주고
& 연산자와 해당 조건셀을 틀릭해서 값 넣어주기! 참조기능 사용!
-> ">="$O24
▶SUMIF 함수
특정 조건을 만족하는 데이터의 합계 계산
▶ SUMIFS 함수
2개 이상의 조건을 만족하는 데이터의 합계 계산 #범위의 높이가 같아야 함!
=SUMIFS( 더할 값들의 범위 , 더할 조건 범위1, 조건 1, 더할 조건 범위 2, 조건 2)
=SUMIFS( 금액 , 연도 , "2023" , 구분 , "매출액")
★ SUMIFS 를 생활화 하자!
★ 피벗테이블은 로우테이블이 바뀌면 자동으로 갱신되지 않음, 우클릭해서 새로고침 해야 갱신됨
피벗테이블은 최종 결과물이 아니라 숫자를 참고하여 다른 자료를 만들때 사용하는 것이 편함
★ 함수로 만들면 로우테이블이 바뀌면 자동으로 갱신됨
▶FIND 함수
긴텍스트에서 특정 단어나 문장이 시작하는 위치를 숫자로 출력
띄어쓰기 포함하여 문자를 세며 대소문자를 구분함
(* 대소문자를 구분하지 않을 때는 SEARCH 함수 사용)
=FIND( "찾을 텍스트" , 긴 텍스트 셀 , [문자열을 찾기 시작할 위치] ) # 위치 생략시 1부터 시작
=FIND( " 아빠 " , A1 , 101 ) # 단어가 몇번째 있는지 알려줌
▶ IFERROR 함수
=IFERROR( FIND( " 아빠 " , A1 , 101 ) , 0) #찾는 단어가 없다면 0을 출력
=COUNTIFS( FIND함수 출력 셀 , " >0 " ) # 0값이 아닌 셀이 몇갠지 셀 수 있다
▶ LEFT, RIGHT 함수
=LEFT(데이터가 입력된 셀, 불러올 문자열 수) # 왼쪽에서부터 N개 가져오기
=RIGHT(데이터가 입력된 셀, 불러올 문자열 수) # 오른쪽에서부터 N개 가져오기
▶ MID 함수
=MID( 데이터가 입력된 셀 , 불러올 문자열의 시작 위치 , 불러올 문자열 수 )
=MID( B5 , 5 ,3 ) # B5에서 5번째부터 3글자 불러오기
▶텍스트 나누기
* - 으로 나누어져 있는 경우
=FIND( "-" , B5 , 1) # -의 위치를 찾기
▶ 응용
AAAA-BBBB-CCCC-DDDD
첫번째 - 위치 : =FIND("-",$B5,1)
두번째 - 위치 : =FIND("-",$B5,$C5+1)
세번째 - 위치 : =FIND("-",$B5,D5+1)
AAAA찾기: =LEFT($B5,C5-1)
BBBB찾기: =MID($B5,$C5+1,$D5-$C5-1)
CCCC찾기: =MID($B5,$D5+1,$E5-$D5-1)
#데이터가 입력된 셀 , 2번째 하이픈 하나다음부터 , 3번째하이픈-2번째하이픈-1개 값만큼 불러오기
DDDD찾기: =RIGHT($B6,LEN($B6)-$E6) / =MID($B5,$E5+1,1000)
날짜 및 텍스트 분리하기
▶ 날짜 데이터 분리하기 1
B1 → 2030-10-10
=YEAR( B1 ) & "년" → 2030년
=MONTH( B1 ) & "월" → 10월
=DAY( B1 ) & "일" → 10일
▶ 날짜 데이터 분리하기 2
2030-10-10 형태로 적고 표시형식을 일반 → 날짜로 변경하기

▶ 날짜 데이터 분리하기 2
CTRL 1 눌러서 표시형식 - 날짜- 에서 YYYY-MM-DD 형식 변경 가능
▶ 텍스트 나누기 1 / '-'
영역선택 - 데이터 - 텍스트 나누기


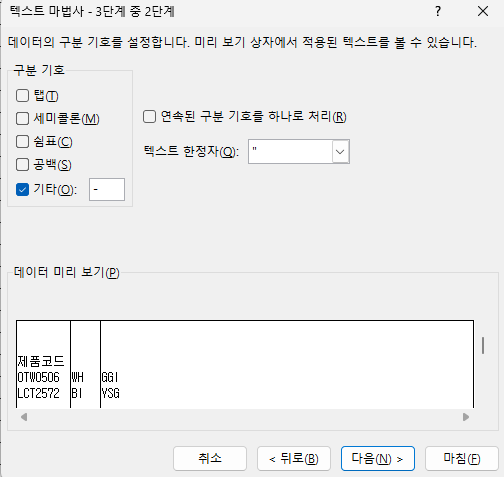
이 방식대로 하게 되면 원본 데이터가 잘림
따라서 원본데이터를 복사해서 열에 붙여넣기후 진행하면 됨!
▶ 텍스트 나누기 2 / '공백'

연속된 구분 기호를 하나로 처리: 연속된 띄어쓰기를 1개의 띄어쓰기로 처리함
▶ 텍스트 합치기 / &
= K5 & L5 & M5
=CONCAT( 범위 드래그)
▶ 필터
ALT D F F
데이터 유효성 검사
▶ 데이터 유효성 검사
특정 셀이나 범위에, 상황에 따라 내가 유효하다고 인정하는 데이터만 입력되게 하는 기능
즉 규칙을 위반하는 데이터가 들어가는 것 방지하기
▶ 데이터 유효성 검사 활용
목록을 만들어서 필터처럼 활용 가능하다


데이터 분석을 위한 통계 지식
▶ 기술통계학과 추론통계학
1. 기술통계학: 데이터의 특징을 나열
2. 추론통계학: 가설설정, 모집단 특성 파악
▶ 귀무가설: 기본적으로 참으로 추정되며 처음부터 버릴것으로 예상되는 가설, A는 B와 같다
▶ 대립가설: 귀무가설을 기각함을 보이면 참임을 보일 수 있다.
양측검정: 제1형 : A는 B는 아니다
단측점정: 제2,3형 : A가 B보다 작다, A가 B보다 크다.
▶ 가설검정의 기준
P-VALUE: 유의확률: 귀무 가설이 맞다는 전제 하에, 표본에서 실제로 관측된 통계치 (=귀무가설과 다른) 와 같거나 더 극단적인 통계치가 관측 확률
귀무 가설이 맞다는 전제하에, 내가 뽑았던 표본이나 실험에서 일어나면 안되는 일이 일어난다면 귀무가설을 기각 할 수 있음(이때 이런 일이 발생할 확률 = 유의확률 = p-value)(귀무가설을 기각하기위한 기준)
귀무가설이 평균 무게 100키로 라고 하면, 표본의 평균 무게도 100키로여야함. 그러나 표본의 평균무게가 30키로 였다면 평균무게가 100키로라는 귀무가설을 기각 할 수 있다는 것임.
T-TEST: 두집단의(또는 한 집단의 전/후) 평균에 통계적으로 유의미한 차이가 있는지 검정
두 집단(또는 한집단의 전,후)의 평균에 유의미한 차이가 있는지 (t-test)
두 환자의 간수치는 모두 100이다,
a환자는 약을 복용하지 않고 b환자는 약을 복용한다.
b환자는 80으로 간수치가 줄어들었다.
이때 100에서 80으로 줄어든게 약에 의한 효과인지, 줄어든 20이 유의미한 효과인지 확인하기
또한 이때 a환자와 b환자의 간수치를 비교하는 것도 가능하고, b환자의 복용 전후를 비교해도된다.
F-검정: 두 집단의 분산에 통계적으로 유의미한 차이가 있는지 검정
F-검정의 귀무가설: 차이가 없다. (P>유의수준) 유의수준=0.05
→ P값이 0.05보다 크므로 두 집단의 분산에 유의미한 차이가 없음
F-검정의 대립가설: 차이가 있다. (P<유의수준) 유의수준=0.05
→ P값이 0.05보다 작으므로 두 집단의 분산에 유의미한 차이가 있음
두 집단의 분산에 통계적으로 유의미한 차이가 있는지 (F-검정)
두 집단의 분산 차이를 검정해 각 상황에 맞는 t-test 방법을 사용
평균은 비슷하더라도 극단적으로 높은 데이터와 극단적으로 낮은 데이터가 섞여져 있다면
분산이 달라졌다는 것을 인지 한 상태로 평균을 비교해야하기 때문에 F-검정을 해야함
p가 0.05보다 크면 두 집단의 분산에 유의미한 차이가 없고
p가 0.05보다 작으면 두 집단의 분산에 유의미한 차이가 있다
F 테스트 진행 후 T 테스트 하기!
단순선형회귀와 다중선형회귀 분석
단순 선형회귀 분석:
독립변수 x가 변할때 종속 변수 y가 어떻게 변하는지 가장 잘 설명해주는 직선을 찾아
그 직선이 x와 y의 관계를 얼마나 설명하고 있는지 분석하는 방법 -> y와 x사이의 1차 방정식 구하기
결정계수: (R^2 , R=상관계수) : 0~1 사이의 값을 가짐, 즉 0% ~ 100%, 높을수록 모델의 설명력을 나타냄,
유의한 F: (p-value) : 귀무가설은 우리가 만든 회귀식이 유의미하지 않다. 대립가설은 회귀식이 유의미 하다를 가지고 가설검정을 한다.따라서 이 유의한 F가 0.05보다 크면 이 모델을 기각해야함. 독립 변수를 버리거나 수정해서 다시 회귀분석을 진행해야함
E-정수 : 매우작은 수
E+정수 : 매우 큰 수
계수: y절편= b , x1 = a (y = ax +b)
다중 선형회귀 분석:
독립변수가 2개 이상일때 종속변수와의 관계를 설명
다중회귀분석은 조정된 결정계수로 본다. 1에 가가울 수록 회귀모델이 실제값을 잘 설명함
유의한 F값이 0.05 미만이면 이 회귀 모델이 유의미 하므로 사용가능함
p값이 0.05보다 작은 변수들이 종속 변수 y에 영향을 미칠것으로 기대되는 변수들
계수: y = ax1 + bx2 + cx3 + Ω
다중선형회귀 분석 순서:
0. 독립변수가 16개 이상이라면 상관분석을 실시하여 값이 높은것을 뽑아 다중회귀분석 실시
1. 모든 변수로 다중 회귀 분석 실시 (단 엑셀에서는 최대 16개까지)
2. 유의미한 변수들로 다중선형회귀 분석 돌리기
3. 각각 단순선형회귀 돌리기
시계열 데이터
시계열 데이터 분석 : 시간의 흐름에 따라 발생괸 데이터를 분석하는 것
정상성: 추세나 계절성을 가지고 있지 않으며, 관측된 시간에 무관한 설질
시계열 데이터는 정상 시계열 데이터와 정상성을 가지고 있지 않은 비정상 시계열로 구
대부분의 시계열 데이터는 비정상 시계열 데이터인데, 비정상 시계열 데이터인 상태로는 분석이 어렵기 때문에
차분이나 다른방법을 활용해 비정상 시계열 데이터를 정상 시계열 데이터로 변환해 분석함
지수 평활법: 현재 시점에 가까운 시계열 자료에 큰 가중치를 주고, 과거 시계열 데이터일 수록 작은 가중치를 둔다.
FORECAST.ETS: 엑셀에서 사용 할 수 있는 지수 평활법 관련 예측 함수
예측하고자 하는 날짜(월별이라면 일은 같은 일로 통일 되어있어야함), 우리가 알고있는 과거 시계열 데이터 전부, 과거 날짜 전부, [계절성주기(년단위면 12, 안적으면 알아서 해주는데 원하는 값이 아닐 수도 있음)], [만약 누락값이 있다면 0으로 넣어줄까(0) 평균값을 넣어줄까(1)], [만약 중복일자가 있다면 합칠거냐 큰거?작은거?평균(1)을 쓸건지])

'• 패스트캠퍼스 데이터분석 부트캠프 12기' 카테고리의 다른 글
| 3. 데이터 분석을 위한 핵심 Tool Python(김상모 강사님)_01 (1) | 2024.01.03 |
|---|---|
| 2. 데이터 분석을 위한 기초 수학/통계(이동훈 강사님)_12 (1) | 2023.12.29 |
| 2. 데이터 분석을 위한 기초 수학/통계(이동훈 강사님)_11 (1) | 2023.12.29 |
| 2. 데이터 분석을 위한 기초 수학/통계(이동훈 강사님)_10 (1) | 2023.12.29 |
| 2. 데이터 분석을 위한 기초 수학/통계(이동훈 강사님)_09 (1) | 2023.12.29 |